Sehr geehrte Damen und Herren,
Im Serve-U Newsletter wird das Projektkonsortium quartalsweise Neuigkeiten, Ergebnisse und Errungenschaften rund um das Forschungsprojekt präsentieren. Wir laden Sie ein, diese Newsletter-Updates sowie die Projekthomepage www.serve-u.at an interessierte Unternehmen und Personen weiterzuleiten.
Im letzten Newsletter hatten wir eine kurze Beschreibung des Projekts gegeben, einschließlich der Konsortiumsmitglieder, der anstehenden Projektaufgaben und der Ergebnisse des Kick-off Meetings. In diesem Newsletter geben wir einen kurzen Überblick über die laufenden Aufgaben im Zusammenhang mit dem Datenmanagement, der Datenqualität und der Stromlastprognose, die als Grundlage für jede anstehende Energiemanagementaufgabe betrachtet werden können. Die folgenden Abschnitte sind nach diesen drei Aufgaben strukturiert.
Datenmanagement SERVE-U
Im ersten Schritt wurden die Anforderungen für die Server Infrastruktur, Datenbank, und Schnittstellen spezifiziert. Es wurde gemeinsam mit den, in AP5, involvierten Projektpartner:innen ein Datenmodell zum besseren Verständnis und zur Spezifizierung, welche Daten für das Projekt wichtig sind und in welcher Form sie verfügbar sein sollen (z.B. Rohdaten oder bereits auf Datenqualität überprüft) erstellt.
Die Grafik unterhalb zeigt die grundlegenden Datenströme die berücksichtigt werden:
- Wetterdaten – und Wettervorhersagen für den jeweiligen Standort des Haushaltes
- Energie Erhalt
- PV Energie Haushalt – die durch die Photovoltaik Anlage generierte Energie welche an den Haushalt geliefert und verbraucht wird
- externer Bezug – der eigene Energiebedarf ist nicht abgedeckt durch die PV
- PV Energie von Energie Gemeinschaft
- Energie von Stromnetz
- Energie Abgabe (PV generiert)
- PV Energie an Energiespeicher
- PV Energie an Energie Gemeinschaft
- PV Energie an öffentliches Stromnetz

Datenqualität SERVE-U
Daten sind die Grundlage für Entscheidungen, z.B. welcher Energieträger zu welcher Tageszeit idealerweise eingesetzt werden soll. Um auf Basis von Datenanalyse vertrauenswürdige und richtige Entscheidungen treffen zu können, ist eine hohe Qualität der zugrunde liegenden Daten essenziell. Niedrige Datenqualität kann zu fehlerhaften Analysen, und infolgedessen Fehleinschätzungen mit hohen Folgekosten führen. Beispiele für schlechte Datenqualität sind:
- Fehlende Werte (z.B. „NaN“, 0, -99)
- Verletzung von Konsistenzbedingungen (z.B. ein negativer Spitzenlastwert)
- Fehler im Zeitformat (z.B. falsche Umstellung von Sommer/Winterzeit)
- Doppelte Einträge (z.B. wenn ein Datensatz zwei- oder mehrfach übertragen wird)
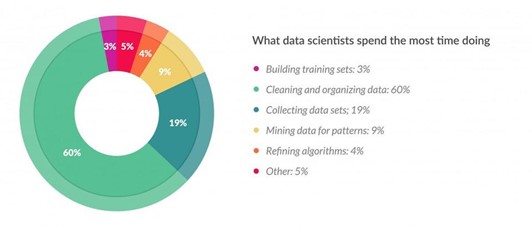
Verschiedene Statistiken zeigen Folgen niedriger Datenqualität sowie der Aufwand, der damit verbunden ist. Laut dem Magazin Forbes[1] beschäftigen sich Datenanalysten zu 60 % ihrer Tätigkeit mit dem Säubern der Daten (sprich: messen und verbessern der Datenqualität) und nur zu 4 % mit dem Finetuning von Analysealgorithmen (ihrer eigentlichen Aufgabe).
Das Thema „Datenqualität“ wird seit den 1980er Jahren ausgehend von Prof. Richard Wang am Massachusetts Institute of Technology (MIT) erforscht und seit damals als Konzept bestehend aus unterschiedlichen Dimensionen beschrieben. Häufig untersuchte Datenqualitätsdimensionen sind die Vollständigkeit (d.h., dass keine Werte fehlen), Konsistenz (dass alle Konsistenzbedingungen eingehalten werden), Eindeutigkeit (dass kein Wert mehrfach vorhanden ist) und Aktualität (dass die Daten zeitgerecht zur Verfügung stehen). Weiters ist es wichtig zu erwähnen, dass Datenqualität immer in einem bestimmten Kontext, das heißt, für eine bestimmte Auswertung oder Domäne wie der Energieeinsatzoptimierung betrachtet wird.
[1] https://www.forbes.com/sites/gilpress/2016/03/23/data-preparation-most-time-consuming-least-enjoyable-data-science-task-survey-says/?sh=7be04e2c6f63
Ziel in Serve-U ist es, ein besonderes Augenmerk auf die Bewertung und Verbesserung der Datenqualität zu legen. Am SCCH wird bereits seit mehreren Jahren an Methoden und Metriken zur Bewertung von Datenqualität geforscht und im Zuge dessen auch zwei Softwaretools[3,4] , entwickelt. Diese sollen nun speziell für die Energiedomäne angepasst werden. Im Zuge des Arbeitspaket 5 soll dabei die Qualität der Quelldaten von unterschiedlichen Partnern (z.B. IKB, Sonnenplatz) einerseits automatisiert bewertet werden, und andererseits Expertenwissen der Konsortialpartner miteinfließen.
Lastprognosen SERVE-U
Der Verbrauch elektrischer Energie und ihre Kosten in Wohngebäuden hängen von mehreren Faktoren ab, darunter die Wetterbedingungen, die Verfügbarkeit erneuerbarer Energiequellen (z. B. Photovoltaik), der Stromverbrauch und die menschlichen Verhaltensmuster sowie der Strompreis. Angesichts der unsicheren Variabilität dieser Parameter kann eine effiziente Stromnutzung nur durch eine kurzfristige Energiemanagementplanung (einige Stunden bis zu einem Tag im Voraus) erreicht werden. Doch selbst für eine solche kurzfristige Planung ist die Ableitung genauer Vorhersagen/Prognosen für diese Parameter eine anspruchsvolle Aufgabe. So können sich zum Beispiel schon kleine Schwankungen in Bezug auf Zeitpunkt und Umfang des Stromverbrauchs nachteilig auf die Leistung der Energiemanagementplanung auswirken.
Frühere vergleichende Analysen von Prognosemethoden durch den SCCH haben gezeigt, dass generische (Black-Box-) Prognosetechniken entweder aufgrund von a) langen Trainingszeiten oder b) der Unfähigkeit, Mustern in den Daten zu entdecken, keine genauen Prognosen liefern können. Aus diesem Grund planen wir im Rahmen von SERVE-U die Weiterentwicklung bestehender Techniken für die Stromlastprognose im Hinblick auf die folgenden Forschungsrichtungen:
a.) Inferenzbasierte Stromlastprognose: Ergänzung von Standardmodellen durch die Erkennung von Mustern im Nutzerverhalten (um so kurzfristige Variationen) besser zu erfassen
b.) Stromlastprognose mit User-in-the-Loop: Berücksichtigung der Auswirkungen von Optimierungsentscheidungen und Informationen über Strompreise auf das Verhalten der Nutzer;
c.) Transfer-Learning-Methoden: Weiterentwicklung von Prognosemodellen durch Integration von Wissen und Daten aus anderen Wohngebäuden.
[3] https://github.com/lisehr/dq-meerkat
[4] Ehrlinger, L., Haunschmid, V., Palazzini, D., & Lettner, C. (2019, August). A DaQL to Monitor Data Quality in Machine Learning Applications. In International Conference on Database and Expert Systems Applications (pp. 227-237). Springer, Cham.
Dieses Projekt wird aus Mitteln des Klima-und Energiefonds gefördert und im Rahmen des Energieforschungsprogramms 2019 durchgeführt. Der nächste Newsletter erscheint Q4/2021.
Für den Inhalt verantwortlich
Cornelia Siedl
Vendevio GmbH
Peter-Behrens-Platz 10
Tel.: +436509920409
Cornelia.siedl@vendevio.com
Dr Lisa Ehrlinger
Software Competence Center
Hagenberg GmbH (SCCH)
Tel.: +43 50 343 836
Lisa.Ehrlinger@scch.at
Dr Georgios Chasparis
Software Competence Center
Hagenberg GmbH (SCCH)
Tel.: +43 50 343 857
Georgios.Chasparis@scch.at


Kontaktadresse
- Michael Schmidthaler
-
Roseggerstraße 15
4600 Wels
Austria - +43 5 0804 10, Fax: +43 50804 11900
- Serve-U.at